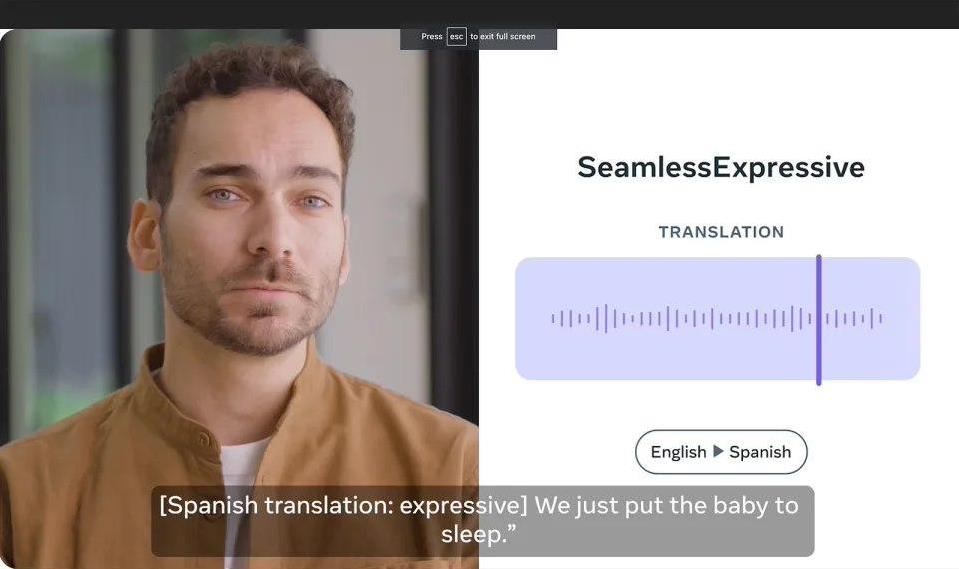

近日,Meta公司推出了多模态人工智能翻译模型SeamlessM4T的“v2”架构,将其称之为“Seamless Communication(无缝沟通)”模型,旨在让对话翻译更加自然和富有表现力。
“SeamlessExpressive”功能可以将说话者的语气、音调、音量、情感色彩、语速和停顿等元素转移到翻译后的语音中。这一突破将为翻译后的语音带来更自然、更生动的表现,无论是在日常生活中还是在内容制作中都将带来极大的帮助。目前,“SeamlessExpressive”支持英语、西班牙语、德语、法语和中文等语言,但演示页面缺少意大利语和中文。
另一个功能是“SeamlessStreaming”,可以在说话者仍在讲话时开始翻译,使其他人能够更快地听到翻译。尽管仍存在不到两秒钟的短暂延迟,但这一功能至少可以在不必等到对方说完一个句子时就开始翻译。Meta公司表示,最大的挑战在于不同语言有不同的句子结构,因此他们必须开发一个专门的算法来研究部分音频输入,以决定是否有足够的上下文开始生成翻译输出,或者是否需要继续倾听。
目前,Meta公司尚未透露公众何时能够使用这些新功能。但可以期待未来,Meta公司将把这些新功能集成到其智能眼镜中,使其更加实用。随着人工智能技术的不断发展,相信未来我们将会看到更多突破性的翻译技术,为跨语言交流带来更加顺畅、自然的体验。
原创文章,作者:秋秋,如若转载,请注明出处:https://www.kejixun.com/article/601894.html